NVIDIA DGX Spark: A Gateway to Extreme-Scale Quantum Computing Simulation on AI Hardware for Chemistry and Drug Discovery

Published on March 16, 2026
Sebastian Yde Madsen, Thomas Kjærgaard, Jógvan Magnus Haugaard Olsen & Casper Kirkegaard
At Kvantify, we develop solutions to real chemistry problems on real quantum computers, continuously working to stay ahead of emerging hardware capabilities. A key prerequisite for operating effectively in this space is the ability to perform quantum simulation at scales representative of physical devices. This is a highly demanding computational task that requires increasingly specialized approaches as qubit counts grow.
Until now, we have kept pace with quantum hardware by developing a proprietary, chemistry-specific subspace simulator. This CPU-based technology has enabled Kvantify Qrunch customers to work efficiently with today’s largest quantum computers. However, it has also become clear that sustaining this trajectory will soon require a massively parallel computing approach.
Many of the recent advances in AI GPUs are also ideally suited for quantum simulation. However, exceptional global demand for AI accelerators has made it difficult to adopt such hardware for emerging application domains. Over the past year, we have therefore explored multiple paths toward integrating GPU acceleration into Kvantify Qrunch. For us, the inflection point came with the release of the NVIDIA DGX Spark, which finally provided an accessible AI-class platform for day-to-day development.
DGX Spark has already proven to be a significant productivity boost for our engineering teams, and we expect it to be equally impactful for customers and application scientists. In this blog post, we share early development results that illustrate why we view DGX Spark as an ideal workstation for large-scale quantum computing simulation.
Convergence of AI and Quantum Computing Infrastructure
Quantum computing and AI share a fundamental computational characteristic: both can be formulated to rely heavily on large-scale tensor operations and extreme memory bandwidth. As a result, many of the same hardware innovations that have accelerated AI workloads are equally transformative for quantum simulation:
- high-bandwidth GPU memory
- tensor core acceleration
- massively parallel compute architectures
- optimized tensor libraries
Datacenter-class GPUs are particularly powerful for these workloads. Their combination of memory capacity and compute throughput makes them well suited for production-scale quantum simulations, allowing the scale of feasible problems to be pushed significantly further. Unfortunately, the exceptional global demand for AI accelerators has made these devices difficult to access, effectively creating a gap between development environments and production deployment.
NVIDIA DGX Spark: Bridging Development and Production
The NVIDIA DGX Spark platform bridges the gap between local development and production deployment by bringing the power of the Grace Blackwell Superchip into a compact workstation form factor. It provides developers with memory capacity and compute characteristics that closely resemble datacenter-class GPUs, enabling realistic performance testing and algorithm development without requiring immediate access to large-scale supercomputing infrastructure.
For quantum computing developers, this is particularly valuable:
- algorithms can be developed and validated locally
- memory-scaling behavior can be tested under realistic conditions
- performance characteristics can be evaluated prior to deployment
- software developed on DGX Spark translates naturally to HPC environments
At Kvantify, we are using DGX Spark to develop support for large-scale quantum chemistry simulation in Kvantify Qrunch. While this functionality is still under active development, we are already seeing how it can significantly accelerate iteration cycles and will enable our customers to target real-world problems at current supercomputing scale.
The Challenge of Quantum Computing Simulation
Simulating quantum computing on classical hardware is a fundamental component of algorithm development, benchmarking, and industrial workflows. The most general and widely used approach is state-vector (SV) simulation, which explicitly represents the full quantum state. While SV simulation applies to arbitrary quantum circuits, it rapidly becomes computationally prohibitive, with runtime scaling as O(G⋅2N) for N qubits and G gates.
In practice, this exponential scaling means that simulations beyond the mid-30 qubit range already require supercomputing resources, and even then it remains challenging to reach meaningful scale for real-world problems.
Recent work illustrates this clearly. For example, simulations of 44 qubits have required thousands of GPUs on systems such as LUMI, highlighting both the raw computational cost of state-vector methods and the limitations they impose on practical quantum application development.
Tensor Networks: A More Scalable Approach for Chemistry
While state-vector simulations remain the most general and straightforward approach, they are not always the most efficient – especially for structured problems such as those found in quantum chemistry. Many quantum chemistry problems exhibit structure that can be exploited using tensor network representations. Instead of storing the full quantum state, tensor networks can compress the state by capturing its entanglement structure. For suitable problems, this can lead to dramatically reduced memory requirements, improved computational efficiency, and scalability beyond traditional state-vector limits. However, it is important to emphasize that the effectiveness of tensor network methods is highly problem dependent.
The quantum algorithms used in Kvantify Qrunch are designed to naturally produce circuits with structure that tensor networks can exploit. Tensor network methods rely heavily on optimized tensor operations – an area where the NVIDIA cuTensorNet library can provide substantial GPU-acceleration. This combination makes GPU-accelerated tensor network simulation an ideal match for our chemistry workloads.
Outlining the state of the art in tensor network–based quantum computing simulation for chemistry is non-trivial for several reasons. While tensor networks can represent quantum circuits exactly in principle, practical scalability is often achieved through controlled approximations such as finite bond-dimension compression. When pushing to even larger system sizes, additional techniques such as embedding or fragmentation schemes are commonly introduced. As a result, most large-scale studies combine tensor networks with some form of approximation, making it difficult to define a single “state of the art,” particularly since tensor network performance already varies strongly with problem structure.
A prominent example of raw scale is the work by Shang et al., who demonstrate extreme-scale quantum computational chemistry simulations on the New Sunway supercomputer. Their approach is based on a custom MPS-VQE simulator capable of running across up to 20 million CPU cores. They report simulations of highly structured systems such as hydrogen chains and ring geometries, with up to ~200 qubits using finite bond-dimension tensor compression. Additional results include more chemically relevant systems at the ~1000-qubit scale, relying on additional approximation via DMET embedding techniques. While technically very impressive, such results depend on national-scale CPU resources and layered approximation strategies, and are difficult to compare directly across problem classes. It is also far beyond the scope of this blog post to compete with such achievements. Instead, our goal is to illustrate how far simulated quantum computing for chemistry can be scaled using exact tensor-network contraction on much more accessible single-device NVIDIA AI hardware.
GPU-Accelerated Quantum Simulation with NVIDIA cuQuantum
To evaluate performance potential and scalability for real-world chemistry workloads on modern AI GPUs, we benchmarked ground-state energy calculations for penicillin. These calculations are performed using our proprietary BEAST-VQE quantum algorithm in Kvantify Qrunch. BEAST-VQE builds circuits iteratively using a heuristic gradient metric for gate selection, as introduced in the FAST-VQE paper, resulting in progressively larger circuits at each iteration.
To isolate the performance of the quantum simulation itself, we exported the quantum circuits generated in the final iteration and used them in a targeted external benchmark program. Based on prior experience, we know that the number of iterations required to maintain constant accuracy typically scales quadratically with the number of qubits. Following this conservative assumption, we configured Qrunch to generate benchmark circuits across a range of problem sizes (e.g., 20 qubits: 14 iterations and 150 gates, including 28 CNOT gates; 70 qubits: 94 iterations and 975 gates, including 188 CNOT gates).
In the benchmark program, we compute the expectation value of the Hamiltonian for these increasingly complex circuits using three different simulation approaches:
- Qiskit state-vector simulation (CPU baseline)
- NVIDIA cuQuantum cuStateVec (GPU state-vector simulation)
- NVIDIA cuQuantum cuTensorNet (GPU tensor-network simulation)
The two state-vector simulators require no special configuration, whereas cuTensorNet exposes a range of tuning options. At a high level, cuTensorNet proceeds in two stages: (1) a contraction path is determined on the host CPU, a(2) the resulting tensor contractions are executed on the GPU. Finding an efficient contraction path is critical for scalability and performance. Since identifying an optimal path is exponentially hard, cuTensorNet relies on heuristics, and the quality of the chosen path directly impacts the computational cost of the contraction. Increasing the effort spent on path optimization can significantly extend the size of solvable problems, but this involves a manual trade-off that is not guided by a clear theoretical framework. For this initial study, we therefore largely relied on default settings and deferred detailed performance tuning to future work.
One parameter we intentionally modified was disabling slicing. While slicing can substantially reduce memory usage by breaking contractions into smaller pieces evaluated one index at a time, we found that it introduced erratic behavior in the benchmark curves, making them difficult to interpret. We therefore disabled slicing to obtain smoother and more comparable performance results.
Benchmarks were conducted on a Dell-branded NVIDIA DGX Spark system, followed by a subsequent run on an AWS P5 instance equipped with an NVIDIA H100 GPU. Each platform offers a distinct balance of compute resources optimized for different numerical precisions, so we benchmarked them according to their respective strengths within the limits of the available library APIs.
The CPU cores of the DGX Spark perform well using standard high-precision floating-point arithmetic, and we therefore ran the CPU baseline using Qiskit’s standard complex128 datatype (i.e., double-precision complex arithmetic, two FP64 values per amplitude). For the chemistry problems targeted by Kvantify Qrunch, the quantum circuits can be expressed using real-valued data types without loss of generality. We therefore used real-valued datatypes for the remaining runs wherever supported by the NVIDIA cuQuantum APIs.
Since GPU hardware delivers substantially higher throughput at lower precision, these simulations were performed using 32-bit floating-point data. On DGX Spark, FP32 provided the best balance between throughput and numerical accuracy. On H100, whose architecture strongly favors tensor core acceleration at reduced precision, we used TF32-accelerated computation with data stored in FP32.
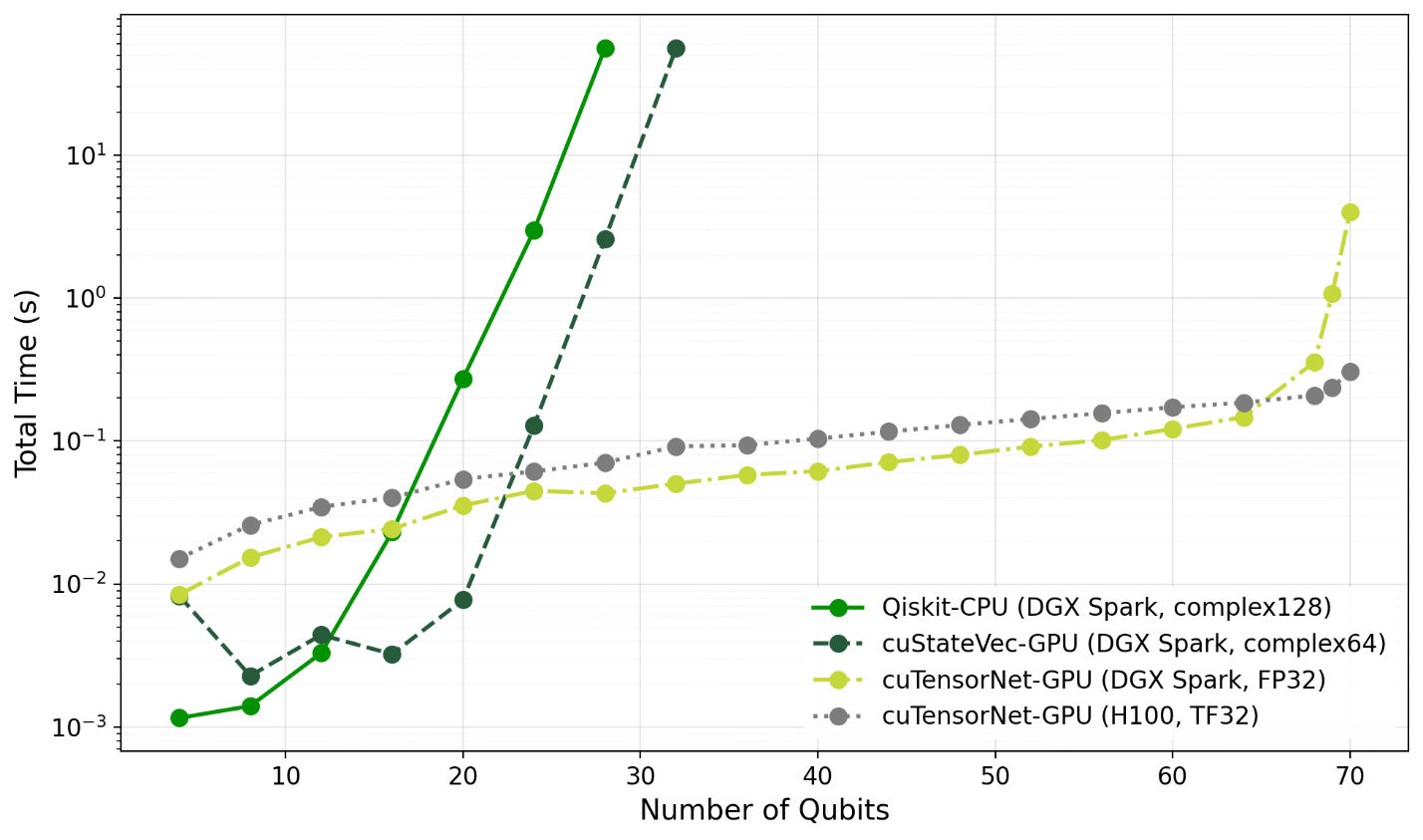
Interpretation of the results above is straightforward for the two state-vector simulators, whereas the cuTensorNet results require more careful analysis. Theory tells us that state-vector simulation scales exponentially with the number of qubits, which is fully consistent with the observed behavior even at relatively modest problem sizes.
For cuTensorNet, there is no simple theoretical scaling law to fall back on, due to the heuristic nature of the contraction path finder. Understanding the trends therefore hinges on how the quality of the generated contraction paths evolves as circuit complexity increases. Across most of the curve, the static configuration of the path finder consistently identifies highly efficient contraction paths. This is reflected in the very low execution times and shallow slope in the early regime, where contraction workloads are handled efficiently by the GPUs and scale favorably with problem size.
Around the 68-qubit mark, this behavior changes abruptly, with both memory consumption and computation time increasing rapidly. This corresponds to the point where the contraction complexity grows sufficiently large that suboptimal path choices dominate overall performance. In this regime, the computational workload becomes large enough to expose the architectural advantages of the H100, which delivers a 13× speedup over DGX Spark at 70 qubits.
Beyond 70 qubits, memory capacity on both devices is exhausted when using the default contraction path settings. This inflection point can be shifted to higher qubit counts by allocating more time to path optimization, and the behavior also changes substantially when enabling slicing. NVIDIA cuTensorNet already supports distributed execution across multiple GPUs, and careful tuning of these parameters is likely to be critical for achieving strong performance at larger scales. Exploring these dimensions is outside the scope of this blog post, however. For now, we simply note the substantial potential for extending quantum simulation beyond a single DGX Spark to larger multi-GPU systems such as NVIDIA DGX SuperPODs.
At a higher level, the results reveal several important trends. First, NVIDIA cuStateVec significantly outperforms Qiskit’s CPU-based state-vector simulation, effectively pushing the exponential scaling wall several qubits higher by leveraging massive GPU parallelism and high memory bandwidth. Second, tensor network simulations using cuTensorNet achieve substantially better performance and scalability than either state-vector approach for the quantum chemistry circuits produced by BEAST-VQE. While computations ultimately still scale exponentially, the inflection point is shifted significantly by allowing tensor networks to implicitly exploit the underlying structure of the problem.
Third, GPU architectures originally designed for AI workloads prove highly effective for quantum tensor-network simulation. Fourth, DGX Spark provides a low-cost, developer-friendly entry point into the DGX ecosystem: its memory capacity and computational characteristics closely mirror higher-end AI systems, enabling realistic development and performance testing for production-scale workloads. Fifth, the cuTensorNet framework already provides the building blocks required to scale simulations developed on DGX Spark onto larger multi-GPU systems such as a DGX SuperPOD.
Finally, it is worth noting that our benchmarks are intended to illustrate the performance potential of each platform when operated near its preferred numerical regime. While the impact of reduced-precision arithmetic warrants deeper investigation, it is not central to the conclusions drawn here. Datacenter-class AI GPUs such as H100 deliver extremely high performance even in FP64, and any constant-factor penalty associated with higher precision is secondary for problems with exponential scaling. In practice, this would simply translate to a modest reduction in feasible problem size to achieve the desired numerical accuracy within a given time budget.
From Workstation Development to HPC Deployment
Using DGX Spark, we are developing simulation capabilities in Kvantify Qrunch that enable customers to explore quantum computing-based chemistry at currently inaccessible scale. The functionality we are implementing supports running large quantum simulation workloads directly on DGX Spark, while also preparing applications for deployment on datacenter-class AI GPUs for even higher performance. For Kvantify and our customers, this workflow is central to building quantum chemistry solutions that scale toward industrially relevant problems.
Our next step is to finalize development and release formal support for NVIDIA hardware in Qrunch, currently planned for Q2. From there, we will extend the platform with distributed computing capabilities. The initial focus is to remain within the NVIDIA DGX framework and prototype multi-node execution using multiple linked DGX Spark systems. This development path provides a direct route to extreme-scale quantum simulation on DGX SuperPOD-class infrastructure, including national systems such as the Danish Gefion supercomputer (1528 NVIDIA H100 GPUs).
By integrating distributed GPU infrastructure with efficient tensor-network algorithms, we aim to raise the bar for what is practically feasible in quantum simulation. Operating at this scale opens the door to more industrially relevant quantum chemistry applications, including:
- drug discovery
- battery materials development
- carbon capture technologies
- bioremediation and environmental chemistry
Get Started with Kvantify Qrunch
Kvantify Qrunch delivers real quantum chemistry on real quantum computers today.
Explore our use case catalog to see how quantum computing can impact industrial chemistry workflows, or try the basic version of Qrunch for free. For more information on our plans for NVIDIA GPU support, please reach out to Stig Elkjær Rasmussen (ser@kvantify.dk).